“阿法狗”第二式:神经网络
2016-08-16
写在前面:
这是一篇CNN(卷积神经网络)的学习笔记,不同之处在于随处可见的数学公式不见了,真的!它的目的不在于把CNN讲清楚,讲清楚CNN不是一篇文章能做到的,更不是碎片时间浏览下就能做到的。目的在于提供一个勾子,一个抹去细节留下方法论的勾子,一个能和现有知识框架搭上的勾子。有了这个勾子,粗,可以窥探时髦的“深度学习”,细,可以为深挖细节做铺垫。
第一式里,卷积核可以理解为滤镜,滤掉无用信息,留下有效特征。但是,构造卷积核却不是一件容易的事。
“这有何难,打开Photoshop,选择‘滤镜-其它-自定义’。”
乱涂乱画,当然不难,做个实用的滤镜看看,做一个不难,做一百个一千个不同类型的滤镜呢?
脏活累活,又极其消耗脑细胞,祖师爷怎么甘心自己动手,于是,毅然踏上了另外一条……更加消耗脑细胞的路,寻找批量新建“滤镜”的方法,便悟出吸星大法般的bug功夫——神经网络。奏是这么牛!
牛在结果,更牛在背后的想法。一般我们都把机器当成提升效率的方式,人工走通流程,然后交给机器大规模地运行这个流程,机器运行的每一步人都了如执掌。而这次不同,老师教会了学生做一件自己都没弄明白的事,学生不仅做到了,而且做得很高效。所以,直播人狗大战时,会听到解说员说:
太聪明了!人是绝对想不到这步的。对,人想不到!!即使想到,需要的时间也远远超过阿法狗。
“吹吧就,BB了这么多,神经网络到底长什么样?”

虽然不是长这样,但它真的是在生物神经元的启发下提出的,所以才叫人工神经网络。
我们试着以识别人脸为例,说明人工神经网络的工作机制。拿出张三、李四、王五三人的头像各若干张,让机器去学习,然后再取几张没见过的照片,让机器判断是谁。
假定每张照片的大小都是100x100像素,把照片直接输入到系统,一个像素都不能少,让神经网络自己抽取特征。这样便有了10k个输入点,分别代表照片上的各个像素,3个输出点,分别代表属于各个人的可能性。
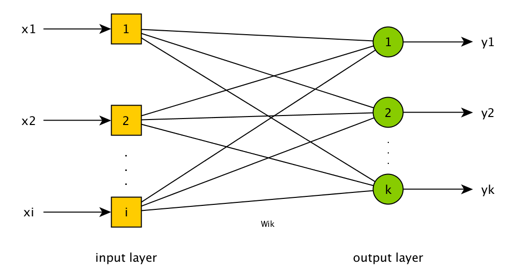
维基百科上解释说,当神经元接收到相连神经元的电信号时,会变得兴奋。神经元之间的连接强度不同,一些足以激活其它神经元,而另一些则会抑制激活。大脑中数千亿神经元及其连接一起构成了人类智能。
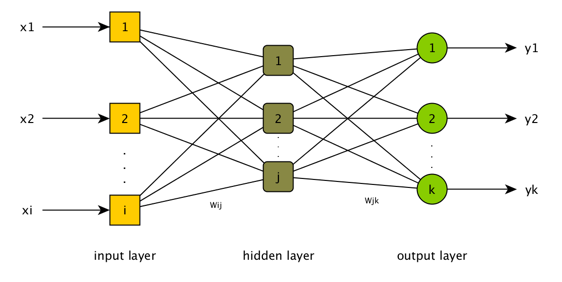
相应地,各个像素对于判断人脸的重要性不尽相同,输入层各节点的取值也各不相同,范围在0到1之间,这体现了神经元之间连接的强度。此外,在输入、输出中间有个隐含层,这是体现神经元互连的层级,也是见证神奇的地方。任意输入节点i和任意隐含节点j建立连接,连接的系数为Wij,任意隐含节点j和任意输出节点k也建立连接,连接的系数为Wjk。
“长得可真不咋滴,又是如何工作的呢?”
很简单,不停地调整连接系数,让结果尽量逼近正确答案,这叫训练。
过程是这样的,把输入层设置为照片的像素,然后以Wij的连接系数传导到隐含层,再以Wjk的连接系数汇总到输出层,输出层中值最大的节点即为这个网络判断的结果。一开始的时候,网络的连接系数是人工设置的,输出的结果肯定不尽如人意,很可能出现,明明给的是张三的照片,在输出层中却是李四对应的节点得分最高。
训练有一个目标函数,可以看成是由所有待求系数Wij为自变量的复合函数,这个目标函数定义了什么样的系数才算一组“好系数”。
“相邻层的任意节点之间都有系数,这么多系数,牵一发而动全身,如何调整才能获得‘好系数’?”
是时候让反向传播出场了。
为了讲反向传播,先绕道说一说负反馈的概念。负反馈,是系统在条件发生变化时作出抵抗该变化的行为。作为自控理论的核心概念,负反馈随处可见。此刻刷着微信的你,一定也吹着空调,空调就是个很好的例子,不停检测实际温度和目标温度的差异,高了就降一降,低了就升一升。
反向传播在想法上与负反馈类似,但具体算法不同,复杂度也不同。输出节点给出的计算值和期望值对比,得出错误,把这个错误,沿网络的相反方向传播,进而校正各个节点的系数,使得全局错误最低。
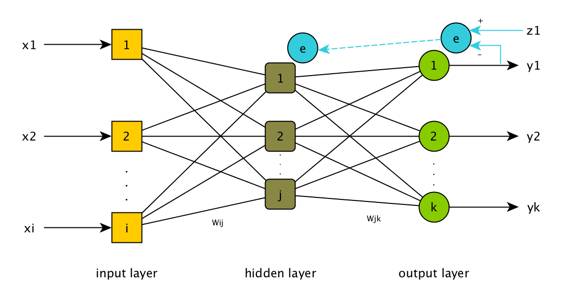
“这个描述也太模糊了,能否再细化下?”
逼我写公式,就不!反向传播算法的核心是,“梯度下降”和“链式法则求偏导”,要通俗地讲可不简单,先挖个坑,哪天悟出了群众喜闻乐见的解释方法,再填上不迟。
总之,如此这般,冬练三九,夏练三伏,错误降为零时,则神功初成。
“听说,有人反复练习了几百万次,错误依然无法降到零……”
这倒有可能,不仅可能,而且是很可能,错误收敛到一个很小的值,也算成功。练得差不多,便可以牛刀小试一番了,拿一张没见过的照片,看它能否辨认出。
“且慢,是不是少了点什么,前面说了神经网络能自动生成卷积核,体现在哪里?”
嘿嘿,隐层那些训练得到的系数,就构成了这个层级定义的过滤函数,也就是卷积核。实际的卷积神经网络有很多个隐层!图片经过一个隐层上的若干过滤器后,就得到了对应数量的特征图谱(feature map),图谱自身其实也是图片,代表了原始图片的某些特征,如轮廓、颜色、亮度,质地等。通常,卷积神经网络的隐层越深,包含的特征图谱就越多,表达能力也就越强。
“原来如此,难怪叫深度学习。”
没错。高深莫测,以至于数十载内,少有人能将其运用自如。
一来对计算能力的要求极高,不是一般的硬件能驾驭,特别是训练一个大型的、高容量的神经网络,CPU也无能为力。近年GPU大行其道后,深度学习才得以流行开来,执其牛耳者,如谷歌,更是在打造机器学习专用的TPU。
二来可解释性不强,像个“黑箱子”一样不知为什么能取得好的效果,不知其所以然,就很难针对性地改进,更别提再上一层楼了。
“哦。阿法狗逼格太高,我还是继续当程序猿吧……”
不,你应该复习下第一式。
微信扫一扫
